I've lost data.
I think most of us have lost data at some point and I want to help people avoid it going forward. So to start off there's a few things to note about data backups.
You should have multiple backups. Backups can be out of date, corrupt, or otherwise unusable. It's also possible backups can be lost at the same time as the source data.
This is also why 'raid is not backup' is a popular phrase in some circles. Raids can seem like a backup but it's possible (even likely!) that you'll lose multiple disks in the array in quick succession. Without multiple backups there is a good chance you'll lose everything anyway.
You should have local and remote backups. If all your backups are local you're still vulnerable to data loss in the event of disasters like theft or fire. If all your backups are remote there are slowdowns when both backing up data and restoring it.
Slow data restores are annoying, but manageable.
However, when backing up data there is an unrecoverable window before data is backed up. The longer this window of time the more data can be lost when your primary storage goes down. Local backups allow this window to be minimized.
Backups are not backups unless they're restorable. The first time I backed up a machine I was 12 years old. This may sound like some great statement of accomplishment, but it's not.
While exploring the capabilities of the system I deleted everything on the hard drive (I was only 12 after all). Backup in hand I felt confident, but unfortunately I had no idea how to restore it or even what application I used to create it.
This is just one way backups may be useless. Backups can be corrupted or messed up in countless ways. It's important to use methodologies that are tried and true. Some common backup utilities have horrific reliability records.
You should also test backups periodically. You should, but realistically I don't expect people to actually do this. The likelihood of people testing is why I rate having multiple backups and the methodology choice as more important decisions.
My Data
I use a Mac as my primary machine. The rest of this post is going to somewhat reflect this. Some of the advice I give will apply if you have Windows, some wont. Regardless the spirit of what I do is the important part.
My data is divided into two major parts. First I have a primary drive which houses the Operating System and the majority of my applications and games. For me this is a 1TB Fusion Drive.
Secondly I have a media drive which houses iTunes library and other similar massive data sets. This is housed in an external Thunderbolt 2 enclosure on a set of four 4TB drives in a Raid 10 array. This gives me roughly 8TB usable.
My Backup Strategy
I actually have two separate strategies.
The Boot Drive
This is my critical data: documents, applications, configurations, my work, my life. I keep three different backups of this data.
First I have a 3TB external drive that I use as a target for Time Machine. This is the native OS X backup solution. It is powerful, reliable, multi-purpose, and revisioned. It keeps old versions of files around for years if space is available. This tier handles several problems stated above. It's local, has a known format, is easy to recover from, and keeps the unrecoverable failure window to (roughly) an hour or less.
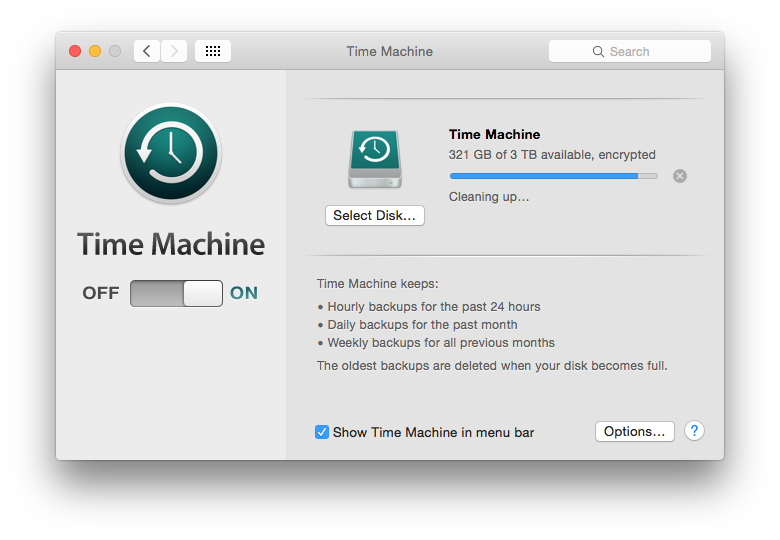
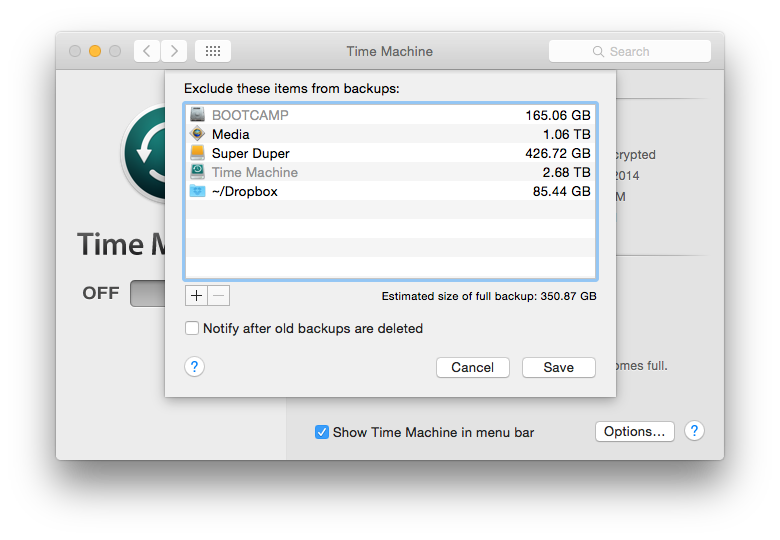
Second I have a 1TB external drive that I use for Super Duper. It's a funny name, but it does something pretty incredible. It creates a bootable clone of primary drive. I can, and have, boot into the clone and copy it back to the main drive. This serves most of the same problems as the Time Machine backup, but the failure window is a day or so. Losing a day of work could be devastating, and way more expensive than an extra external drive.
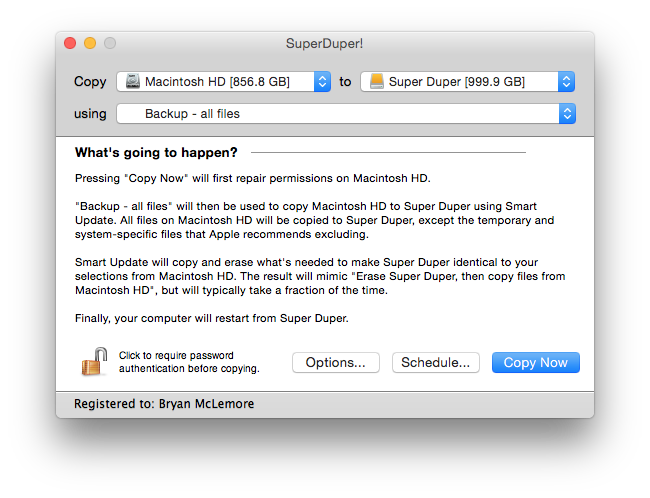
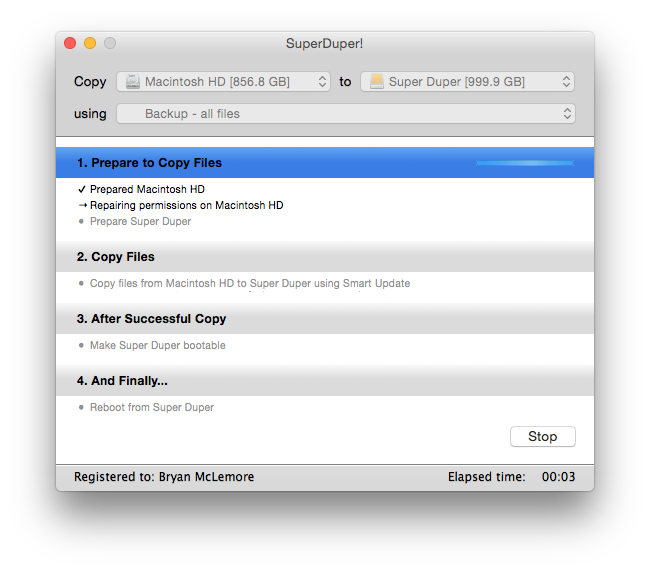

Third I have Backblaze. This piece I use for both drives, and I'll mention it more below.
The Media Drive
This data I frankly consider less critical. I can restore just about everything on here without any backups given enough time, but it's a major hassle to get it all back and straight again. Consequently I have less protection on this data.
As mentioned this data is stored on a Raid 10 array. The raid is my First tier of backups for this drive. I know that 'raid is not a backup', but when used correctly it actually can be a good first step.
I could write a whole post about Raid setups and how to use them effectively. The short story is that Raid 0 is horrific for data reliability, Raid 5 and 1 have rebuild issues if the disk is bigger than about a Terabyte, and Raid 6 and 10 are pretty good. Raid 6 has less waste, but only past 4 disks. This is why I used Raid 10, although honestly Raid 6 may have been better from a fault tolerance standpoint.
As mentioned earlier I use Backblaze for this drive as my Second tier backup.
My Recommendations for You
My setup is probably too complex for most users. Especially those who may not be the most tech savvy. So here's a few basic recommendations for you to take away from this ramble.
First sign up and use a cloud based backup. I've used several, and obviously I recommend Backblaze.
- It's affordable at $5 a month per computer. There's no per gigabyte storage costs.
- It's native on multiple platforms; heavy cross platform apps bother me.
- Uploads are not throttled on Backblaze's end.
- Restores are straight forward downloads.
- If you need 'fast' recovery of a ton of data they can ship you a drive (for the cost of the drive).
Full disclosure the links I've been putting here in Backblaze are referral links. You use them, I get a free month. You don't have to, but it'd be appreciated.
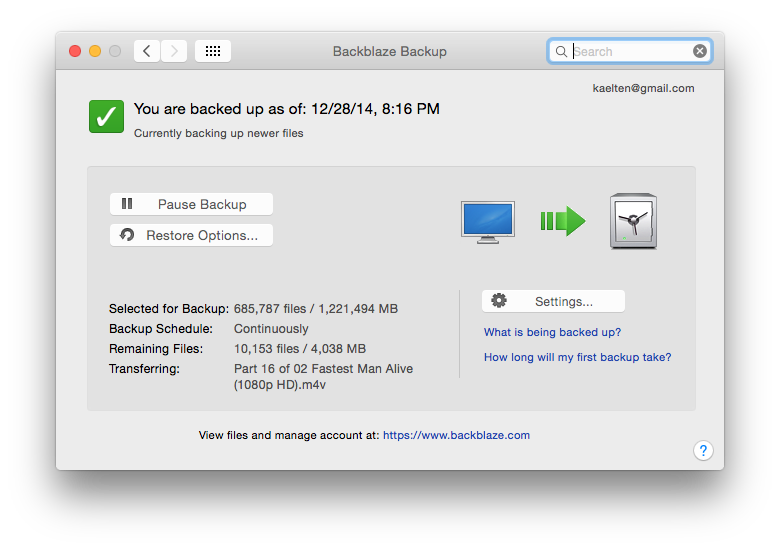


Second use a local backup too. On a Mac Time Machine and Super Duper are both great options. On Windows there's a built in option, but discussions with many people tell me it has questionable reliability. There's a lot of other off the shelf options, but I'm not sure which to recommend. Having one at all is more important than having the best. Don't less analysis paralysis stop you.
I hope this post helps at least one person avoid losing data whether it's your saved games, hours of development, or your kid's birthday photos.